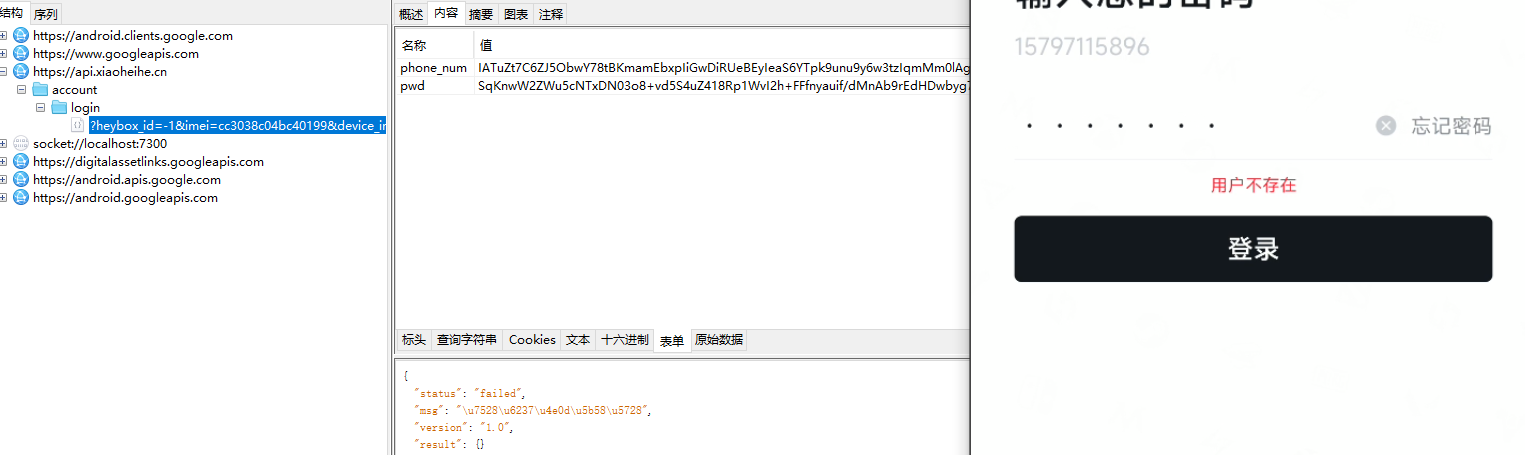
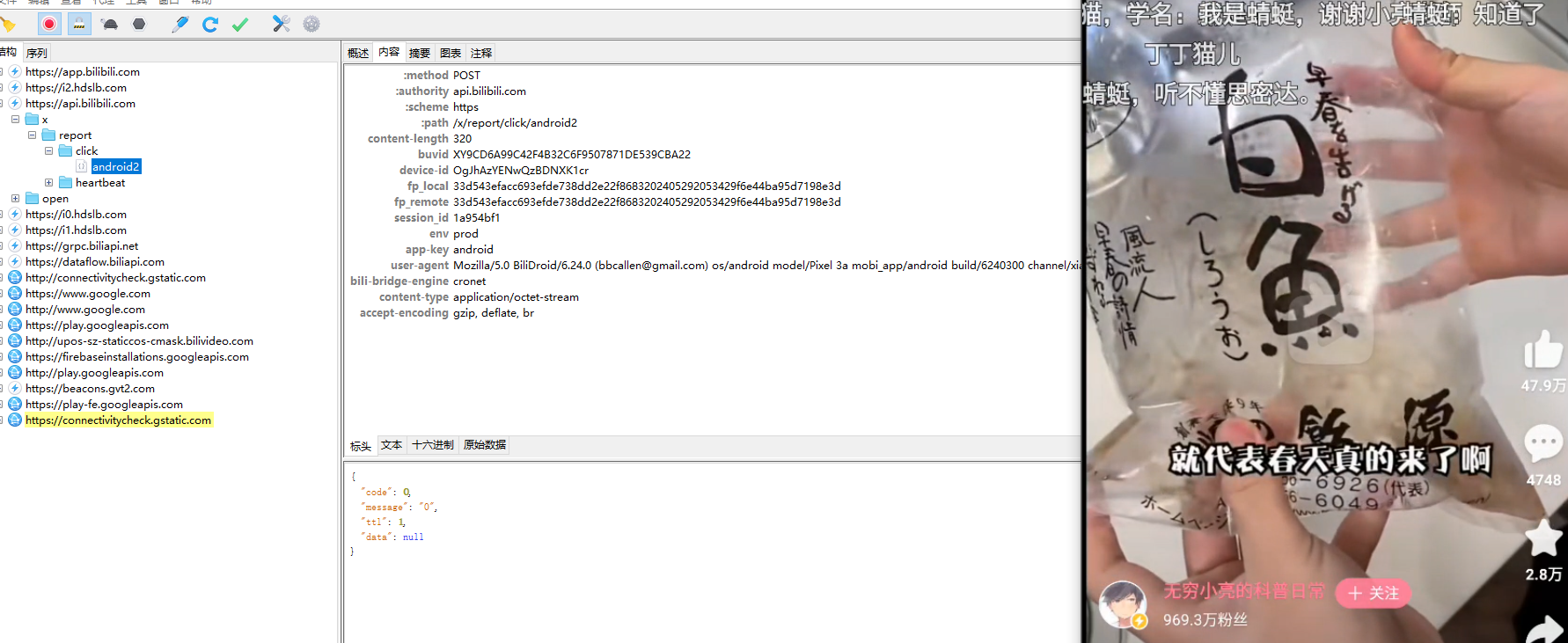
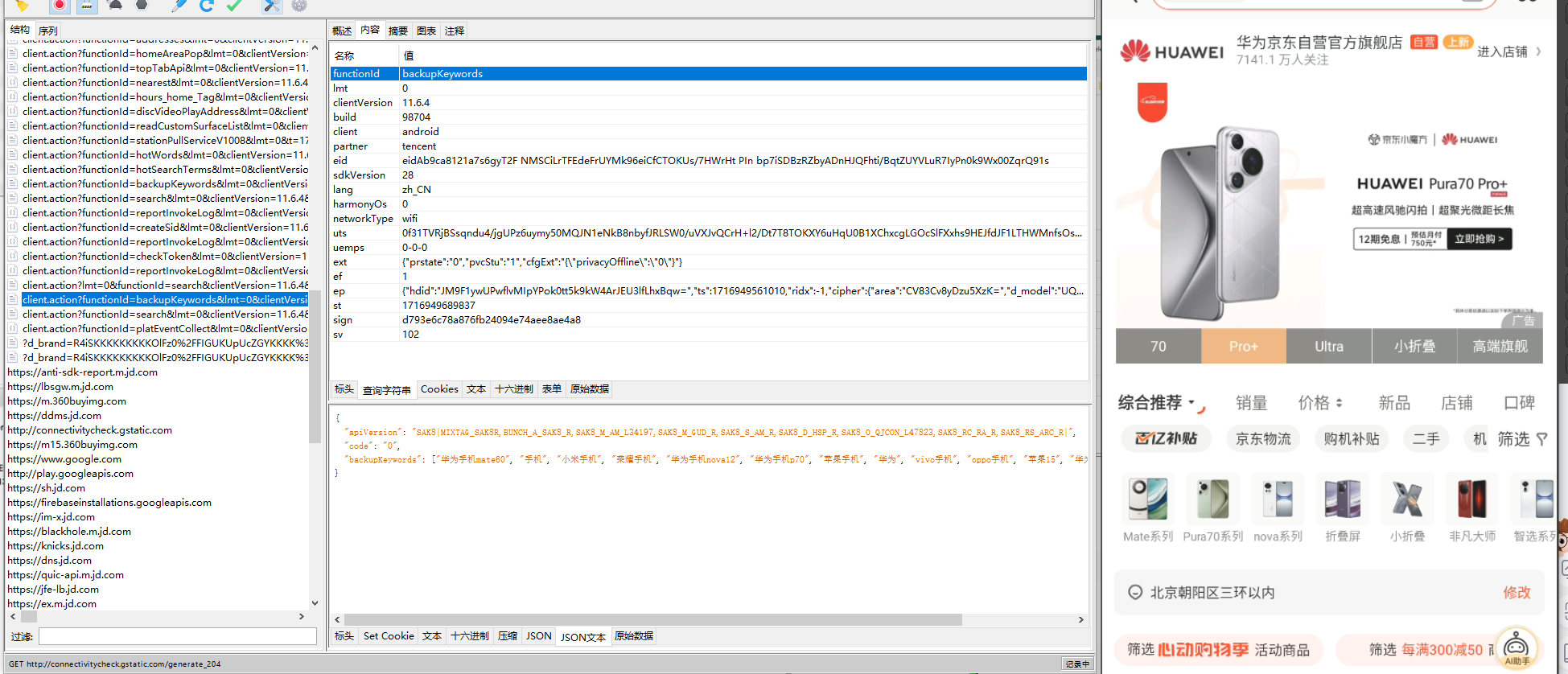
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| req_url = '/api/datalist/financiallist'
req_data = {
"keyNo": "5dffb644394922f9073544a08f38be9f",
"type": "hk",
"reportType": 1,
"currency": "CAD",
"rate": 1
}
win_tid = 'c5c144235c8441642f9af0413f60588e'
def seeds_generator(s):
seeds = {
"0": "W",
"1": "l",
"2": "k",
"3": "B",
"4": "Q",
"5": "g",
"6": "f",
"7": "i",
"8": "i",
"9": "r",
"10": "v",
"11": "6",
"12": "A",
"13": "K",
"14": "N",
"15": "k",
"16": "4",
"17": "L",
"18": "1",
"19": "8"
}
seeds_n = 20
if not s:
s = "/"
s = s.lower()
s = s + s
res = ''
for i in s:
res += seeds[str(ord(i) % seeds_n)]
return res
def a_default(url: str = '/', data: object = {}):
url = url.lower()
dataJson = json.dumps(data, ensure_ascii=False, separators=(',', ':')).lower()
hash = hmac.new(
bytes(seeds_generator(url), encoding='utf-8'),
bytes(url + dataJson, encoding='utf-8'),
hashlib.sha512
).hexdigest()
return hash.lower()[8:28]
def r_default(url: str = '/', data: object = {}, tid: str = ''):
url = url.lower()
dataJson = json.dumps(data, ensure_ascii=False, separators=(',', ':')).lower()
payload = url + 'pathString' + dataJson + tid
key = seeds_generator(url)
hash = hmac.new(
bytes(key, encoding='utf-8'),
bytes(payload, encoding='utf-8'),
hashlib.sha512
).hexdigest()
return hash.lower()
print('key: ' + a_default(req_url, req_data))
print('val: ' + r_default(req_url, req_data, win_tid))
|