网址:https://match.yuanrenxue.cn/match/3
解析流程
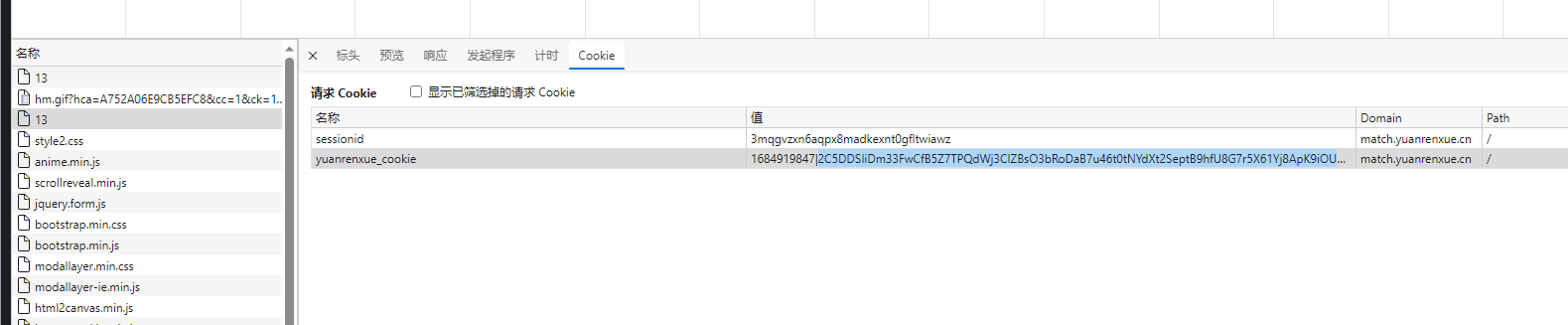
我们直接抓包,发现cookie并不会发生变化,也没有需要解析的请求体,我们直接复制响应再python里面运行一下

发现了一大堆类似类似于jsfuck一样的混淆
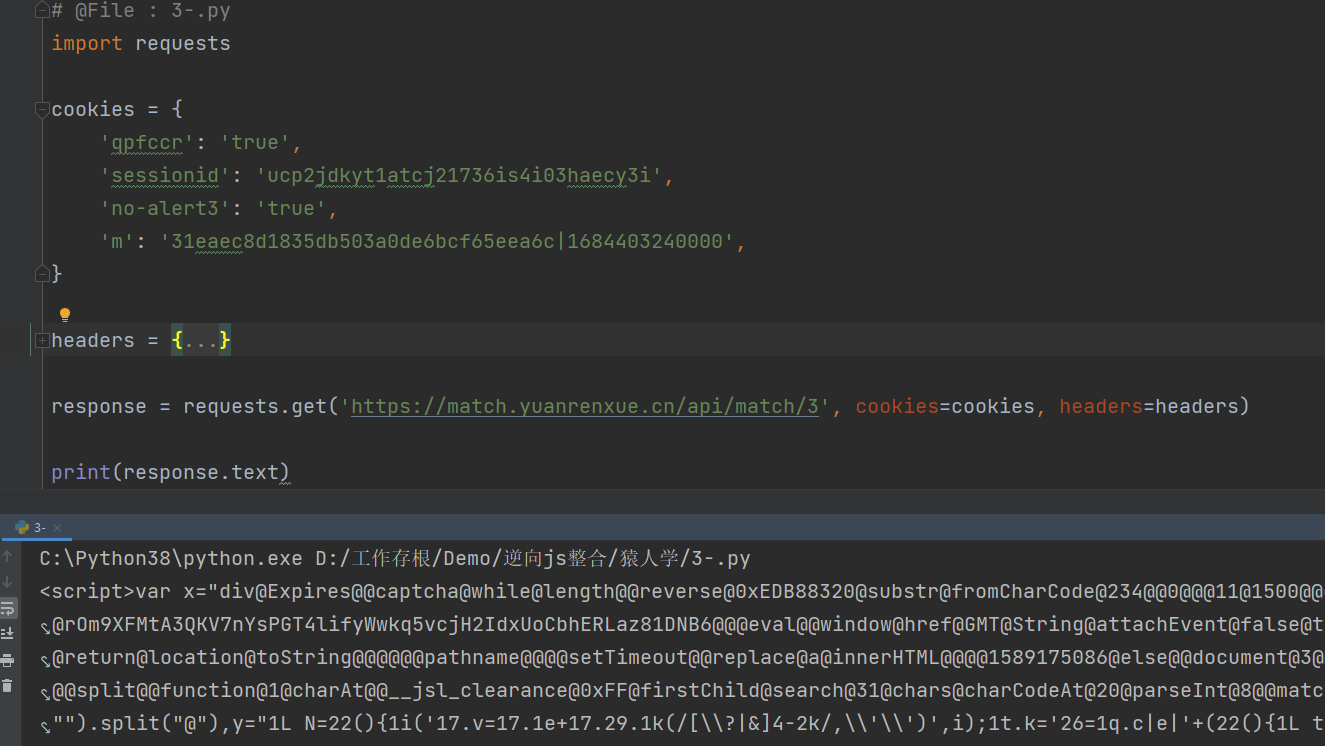
我们用fiddler再试一下,发现fiddler也能正常获取响应
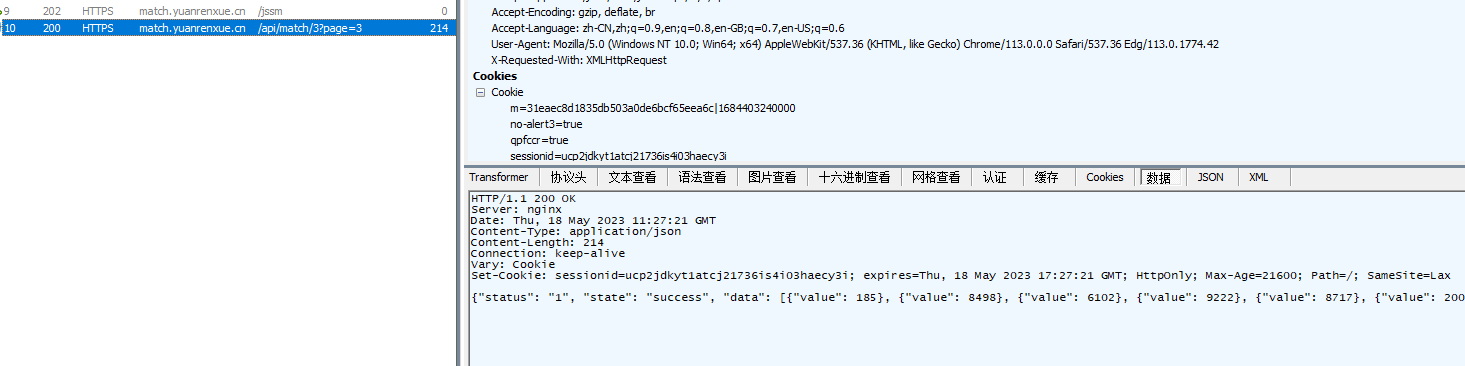
我们再fiddler上重新发起响应看一下,发现竟然返回的和我们再pycharm上的一样
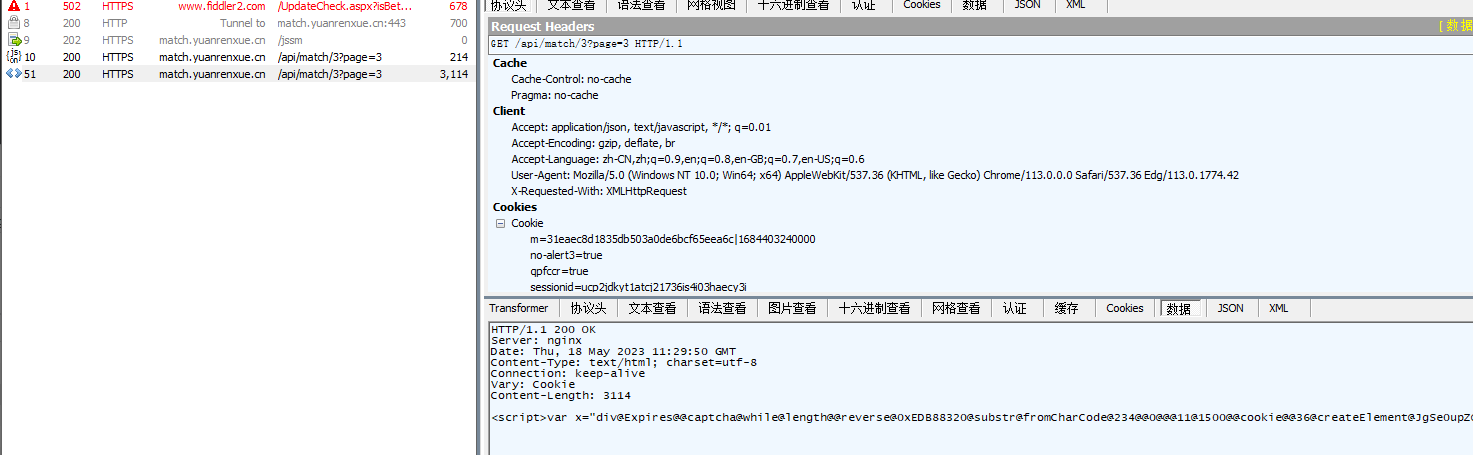
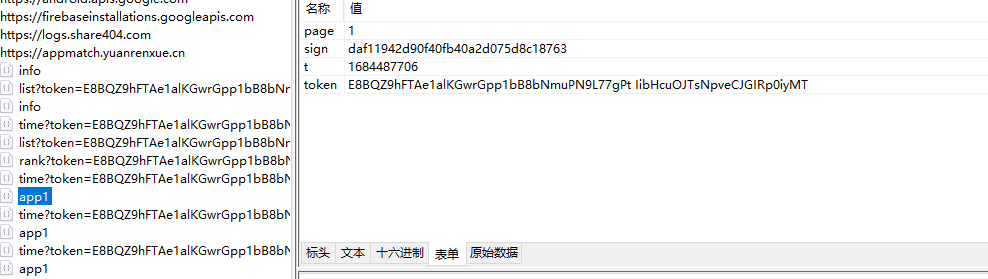
怀疑可能跟上面的jssm请求有关,我们直接在fiddler上同时发起两个请求试一下
这一次正常返回了响应,我们在py里面用session把这两个都请求一下
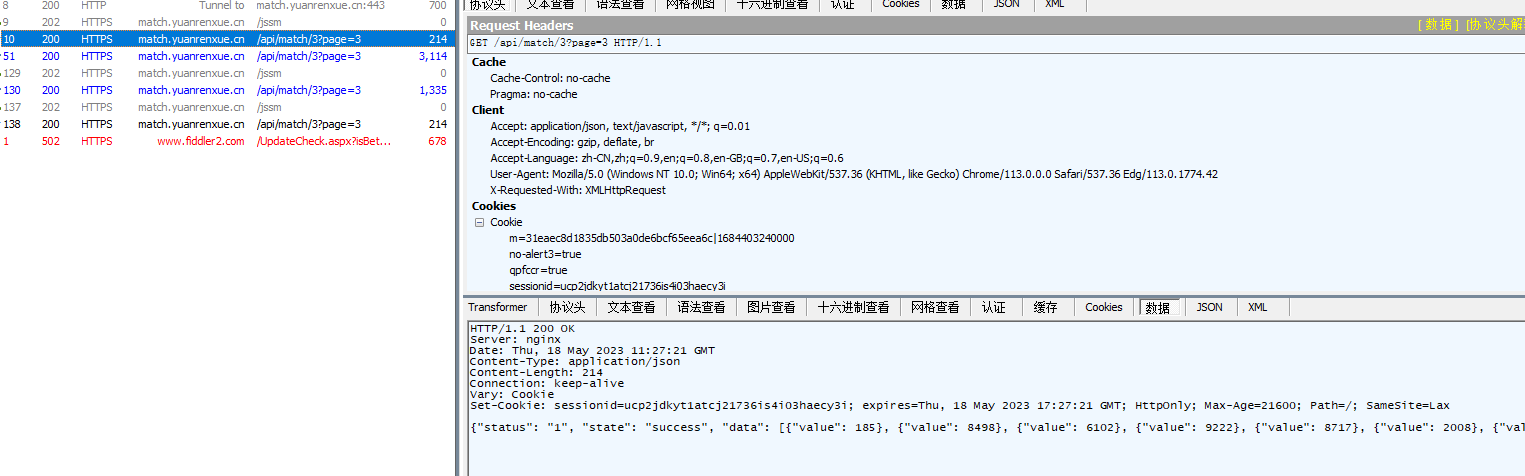
需要注意的是,headers不要跟着session一起请求,百度了一下说是跟着一起请求会打乱headers字段里面的顺序,然后又拿不到正确的响应,需要在请求之前 用session.headers = headers设置请求头
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| import requests
from collections import defaultdict
headers = {
'content-length': '0',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'sec-ch-ua': '"Google Chrome";v="111", "Not(A:Brand";v="8", "Chromium";v="111"',
'sec-ch-ua-mobile': '?0',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
'sec-ch-ua-platform': '"Windows"',
'accept': '*/*',
'origin': 'https://match.yuanrenxue.cn',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': 'https://match.yuanrenxue.cn/match/3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
}
cookies = {
"sessionid": "ucp2jdkyt1atcj21736is4i03haecy3i",
"qpfccr": "true",
"no-alert3": "true",
}
session = requests.session()
session.headers = headers
res = defaultdict(int)
for i in range(1, 6):
url = "https://match.yuanrenxue.cn/jssm"
response = session.post(url, cookies=cookies)
url_p = 'https://match.yuanrenxue.cn/api/match/3?page={}'.format(i)
resp = session.get(url=url_p, cookies=cookies)
print(resp.text)
for data in resp.json()['data']:
value = data['value']
res[value] += 1
print(res)
print(dict(res))
print(max(res, key=lambda x: res[x]))
|