网址:https://match.yuanrenxue.cn/match/4
解析流程
正常抓包,多请求几次,没有其它加密,问题出在响应数据里面
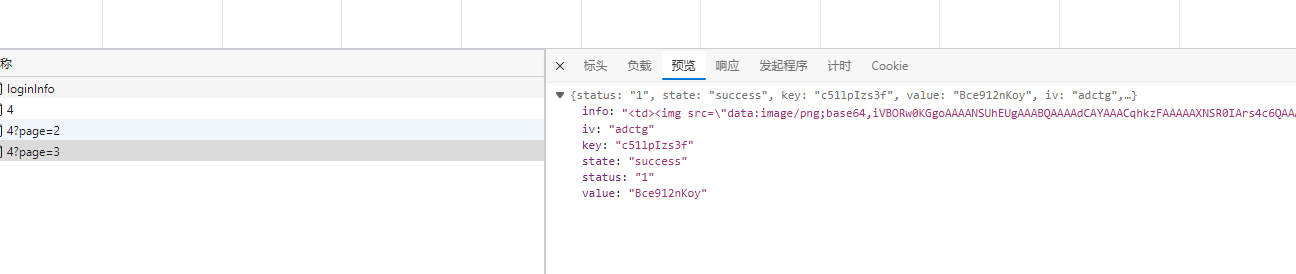
我们把info拿出来看一下,以为分割,切看来看一下,10组数据,对应应该是浏览器里面的十组数字

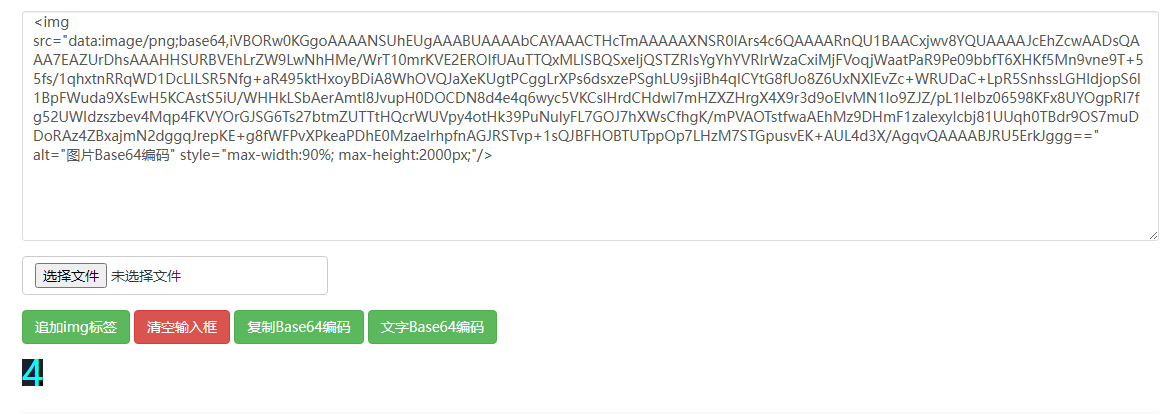
再从每一组里面拆开来,每组里面图片数量不等,和浏览器里面也对不上,复制一份用在线网页展示一下

现在可以理清的是,每次请求会返回十组数据,每组有数量不同的图片base64编码,我们回到浏览器查看一下
发现浏览器中也是数量不对 但顺序是对的,对不上的图片做了样式隐藏,所以我们要找一下样式是怎么处理的
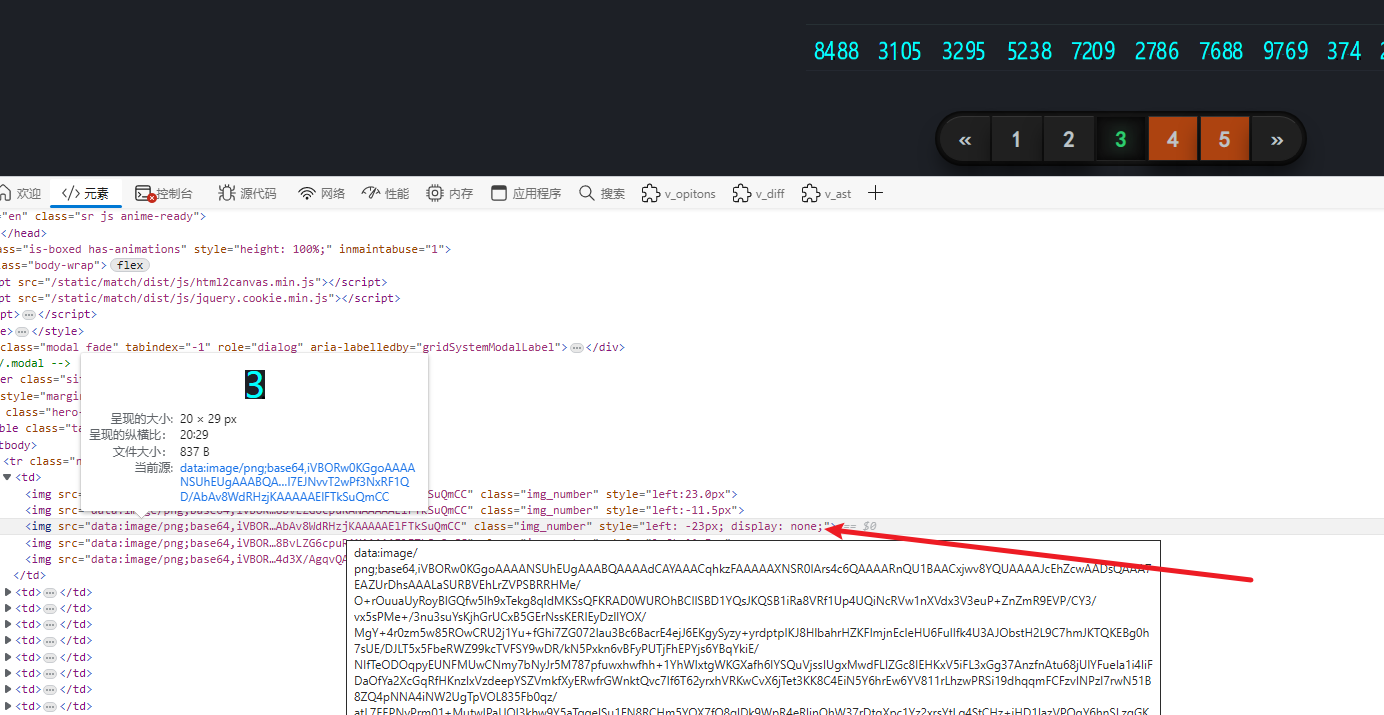
直接添加xhr断点,跳到reques这里来
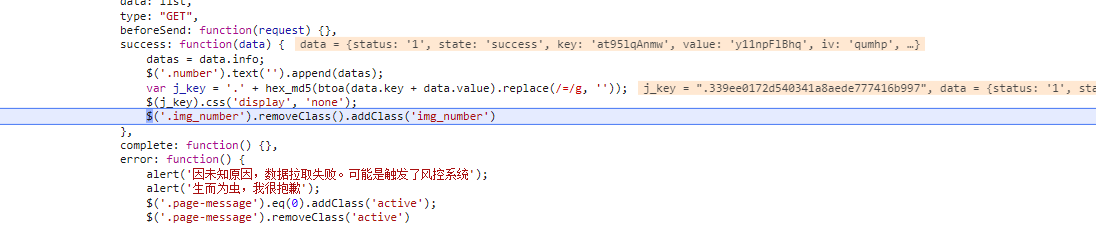
看一下这段代码,j_key的话是接口返回的key和value进行base64加密然后在进行md5加密,然后去掉=再加上·,这里的意思是,如果接口中返回的数据里面的img_number的值等于,那么就加上display: none;,将其隐藏
1
2
3
| var j_key = '.' + hex_md5(btoa(data.key + data.value).replace(/=/g, ''));
$(j_key).css('display', 'none');
$('.img_number').removeClass().addClass('img_number')
|
至于图片顺序,我们同样看style标签,第一个的值是0px,然后没加一个增加11.5个像素
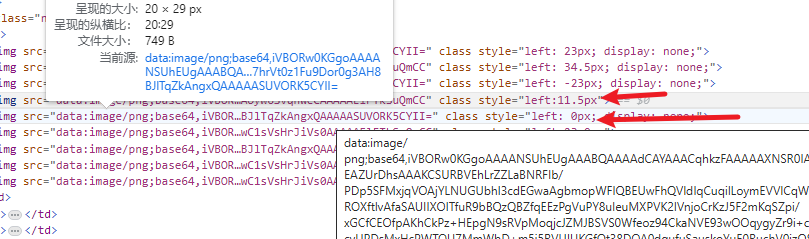
我们验证接口中返回的数据,能发现,去除掉需要隐藏的图片后,返回的正确顺序应该是接口返回的left:值再加上返回的顺序*11.5
而对于图片内容,通过观察固定的数字是固定的base64编码,所以我们只需要把0-9的编码都拿出来组合成字典即可
我们直接上代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
| import base64
import hashlib
import re
import requests
def find_keys(dict, val):
return list(key for key, value in dict.items() if value == val)
img_dict = {"xxx":1,
"xxx2":2....}
cookies = {
'Hm_lvt_c99546cf032aaa5a679230de9a95c7db': '1684209703',
'Hm_lpvt_c99546cf032aaa5a679230de9a95c7db': '1684209703',
'qpfccr': 'true',
'no-alert3': 'true',
}
headers = {
'authority': 'match.yuanrenxue.cn',
'accept': 'application/json, text/javascript, */*; q=0.01',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'referer': 'https://match.yuanrenxue.cn/match/4',
'sec-ch-ua': '"Microsoft Edge";v="113", "Chromium";v="113", "Not-A.Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.42',
'x-requested-with': 'XMLHttpRequest',
}
all_num = 0
for page in range(1,6):
params = {
'page': page,
}
response = requests.get('https://match.yuanrenxue.cn/api/match/4', params=params, cookies=cookies,
headers=headers).json()
key = response['key']
value = response['value']
bs64_value = base64.b64encode((key + value).encode()).decode().replace('=', '')
md_value = hashlib.new('md5', bs64_value.encode('utf-8')).hexdigest()
info = response['info']
td_list = re.findall(r'<td>.*?</td>', info)
page_num = 0
for td in td_list:
img_urls = re.findall(r'src="(data:.*?)" class="img_number (.*?)" style="left:(.*?)"', td)
num_list = []
order_list = []
num = 0
for img in img_urls:
if md_value not in img[1]:
order_list.append(int(float(img[2].replace("px", "")) + 11.5 * num))
num_list.append(img_dict[img[0]])
num += 1
order_list2 = sorted(order_list)
true_list = []
for v in order_list2:
index = order_list.index(v)
true_list.append(num_list[index])
true_num = int(''.join([str(i) for i in true_list]))
page_num += true_num
all_num+= page_num
print(all_num)
|