protobuf是json和xml相识的数据通信协议,提供了高效率的序列化和反序列化机制,序列化就是将数据转换成二进制发送个服务器,反序列化就是将接收到的二进制转换成对应的对象
网站:https://s.wanfangdata.com.cn/
接口:https://s.wanfangdata.com.cn/SearchService.SearchService/search
解析流程
我们打开网站进行搜索,网页并没有刷新,说明可能是xhr请求,我们看一下,这个search结尾的接口比较符合
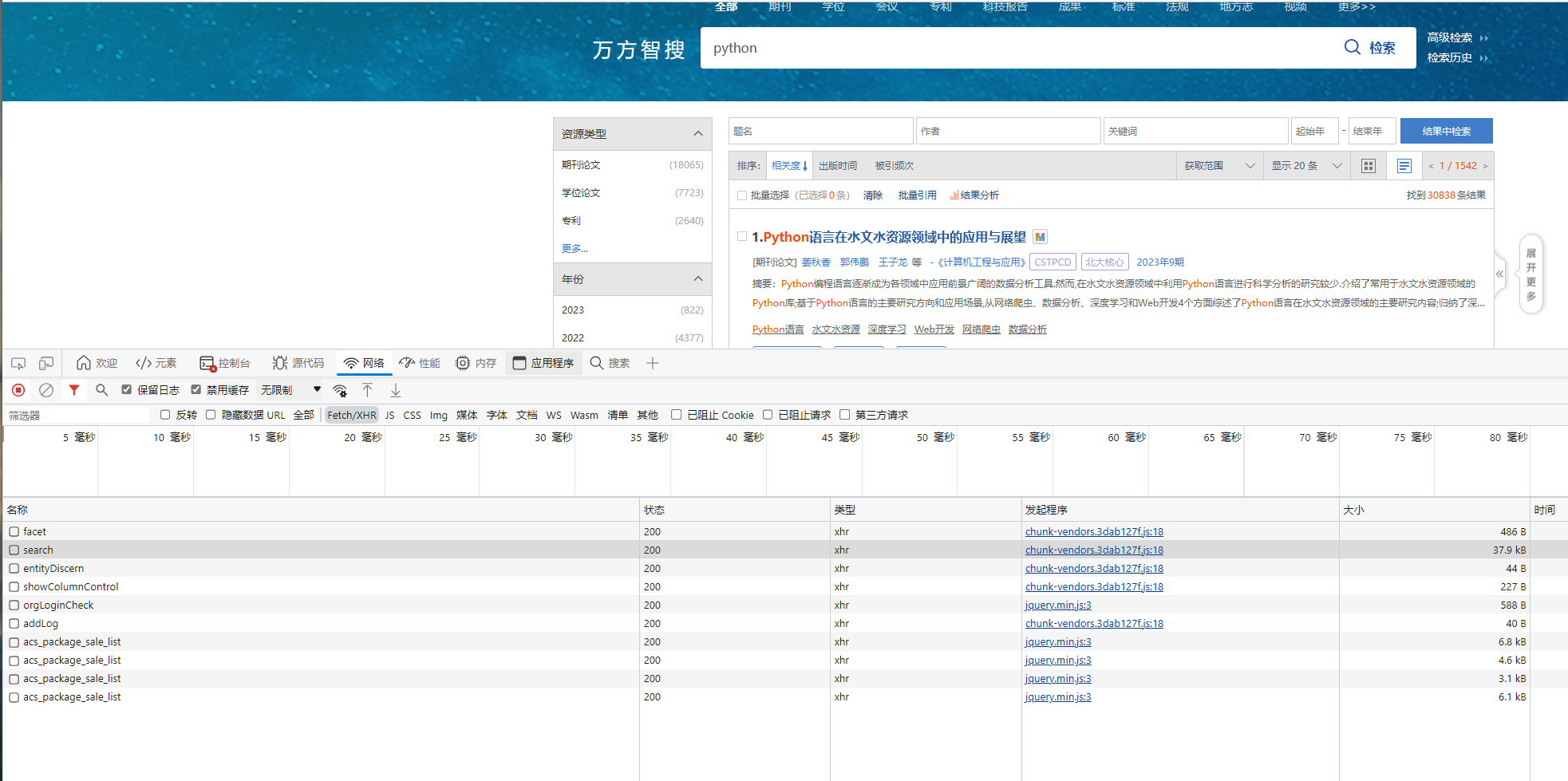
我们能看到他这里的响应头带了一个 application/grpc-web+proto proto是 protobuf协议的简称,我们在看一下请求头和响应数据,看上去好像都是乱码,我们从发起程序处开始跟栈
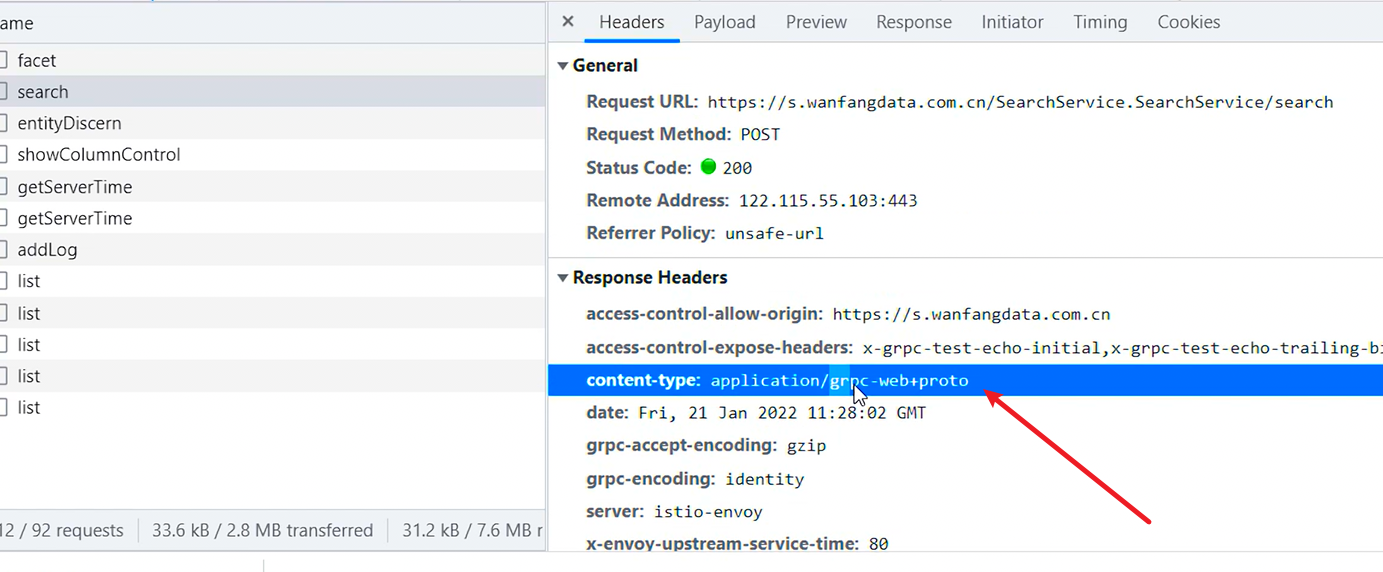
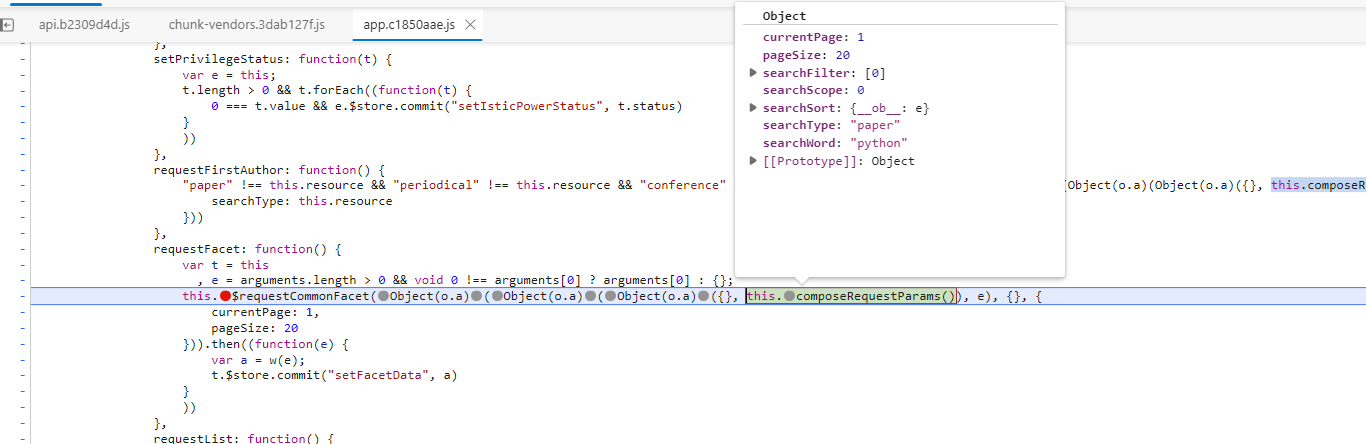
我们跟栈要找一下跟我们搜索的关键字有关的代码,这里看上去有点像原始的请求头数据,我们先把它复制下来
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| {
"searchType": "paper",
"searchWord": "python",
"currentPage": 1,
"pageSize": 20,
"searchFilter": [
0
],
"searchSort": {
"field": "",
"order": 1
},
"searchScope": 0
}
|
我们在下面可以看到有个t,这个t就是页面加载的数据,这里看到的是已经反序列化后的数据
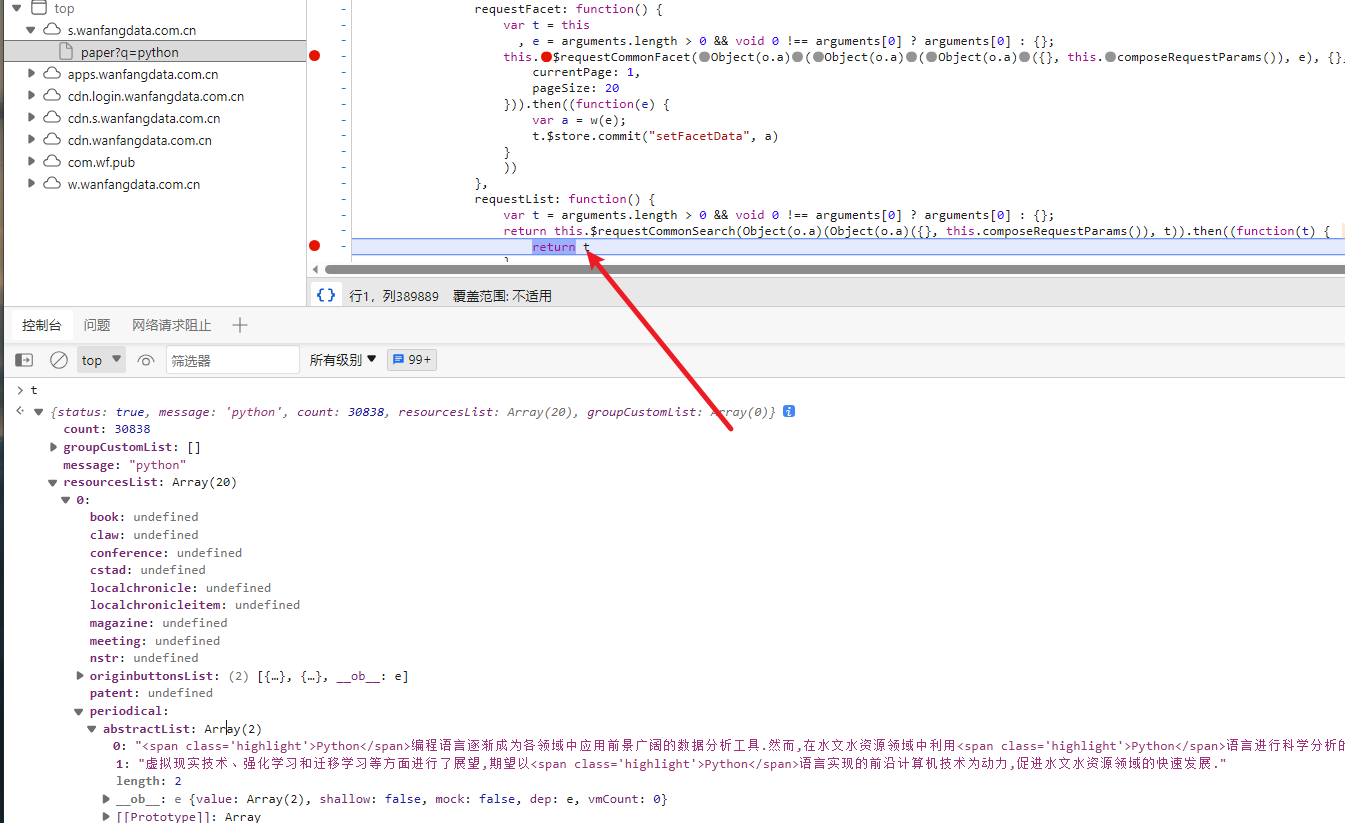
接下来我们要开始编写proto文件,就是更具请求体数据来编写对应的proto格式
最上层的 syntax = "proto3"; 代表确定proto使用的协议
下面就是消息体,由message进行标识,数据类型需要转换成proto type类型, 名称就是具体的数据键值对中的键,=号后面的数据就是它在数据中的顺序位置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| syntax = 'proto3'; //固定写法
message SearchService{
enum SearchFilter {
A = 0;
}
message CommonRequest {
message SearchSort {
string B = 1;
int32 C = 2;
}
string searchType = 1;
string searchWord = 2;
int32 currentPage = 3;
int32 pageSize = 4;
repeated SearchFilter searchFilter = 5;
repeated SearchSort searchSort = 6;
int32 searchScope = 7;
}
message SearchRequest{
CommonRequest commonRequest = 1;
}
}
|
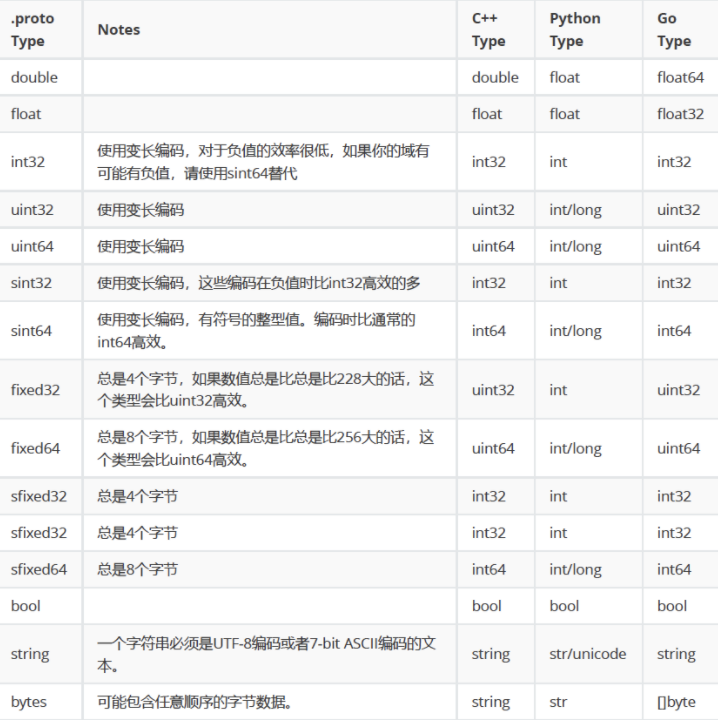
然后使用下载下来的protoc.exe程序进行转换,转换命令是 .\protoc.exe --python_out=../params.proto
执行完成后会生成一个后缀是pb2.py的文件,这个文件就是用来进行protobuf数据编译的
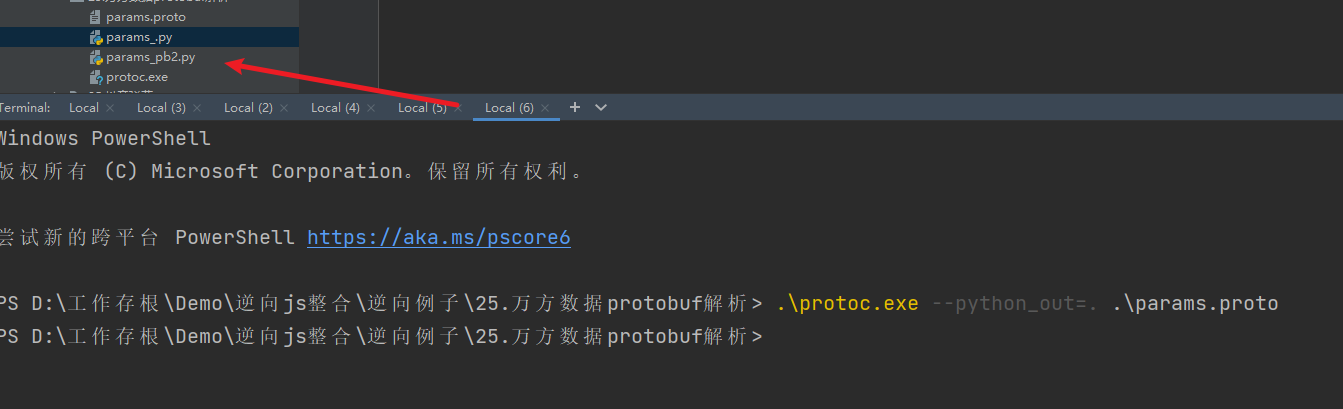
接下来编写python代码,这一段是用来导入转换后的请求数据,searchRequest 是一个类似字典的东西,就是我们请求头转换后的数据
1
2
3
4
5
6
7
8
9
10
11
| commonRequest {
searchType: "paper"
searchWord: "python"
currentPage: 1
pageSize: 20
searchFilter: A
searchSort {
B: " "
C: 1
}
}
|
接下来编写请求代码,一定要携带 application/grpc-web+proto
1
2
3
4
5
6
7
8
9
| url = 'https://s.wanfangdata.com.cn/SearchService.SearchService/search?'
headers = {
'origin': 'https://s.wanfangdata.com.cn',
'Content-Type': 'application/grpc-web+proto',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36',
'x-grpc-web': '1',
'x-user-agent': 'grpc-web-javascript/0.1'
}
|
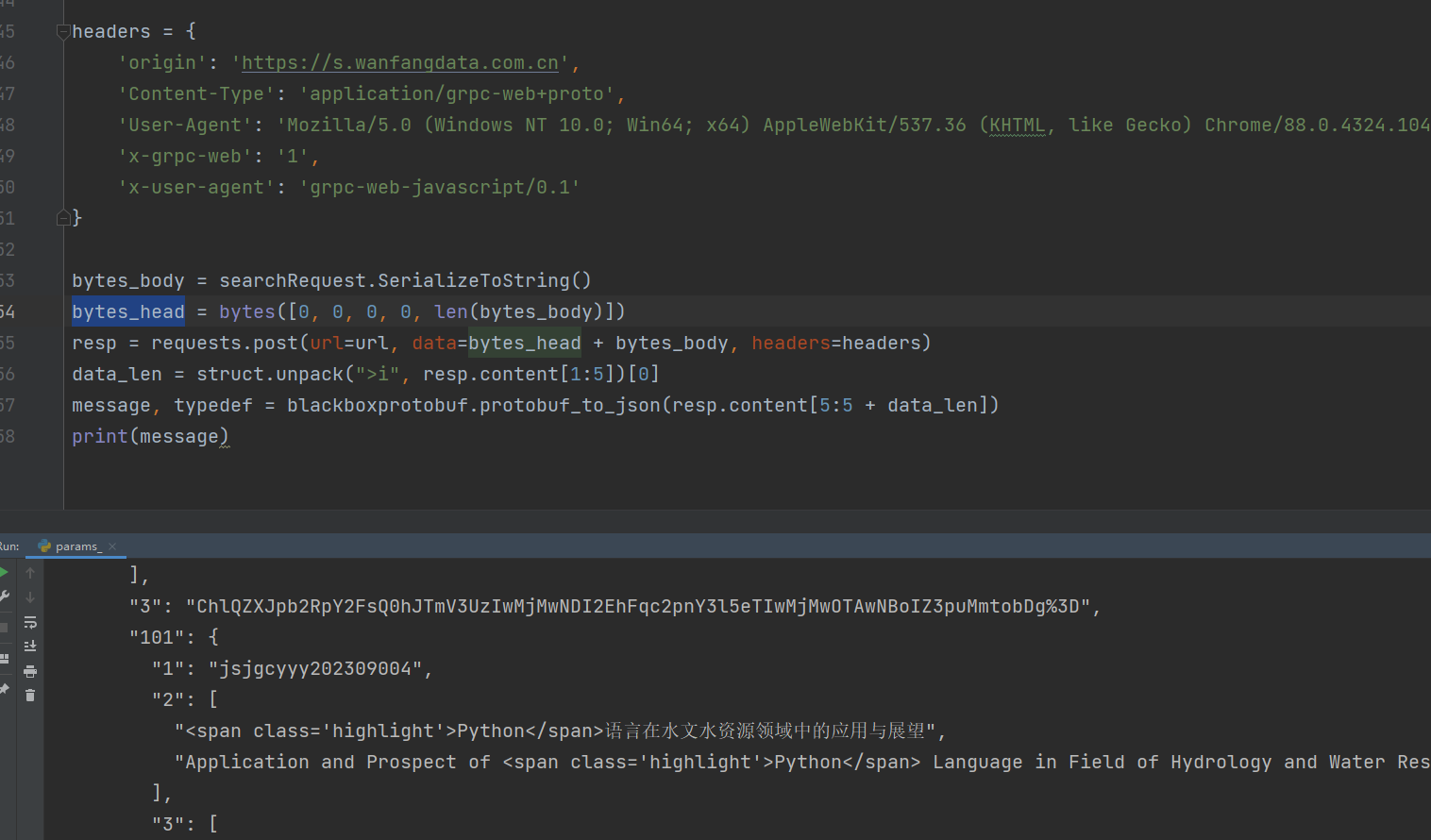
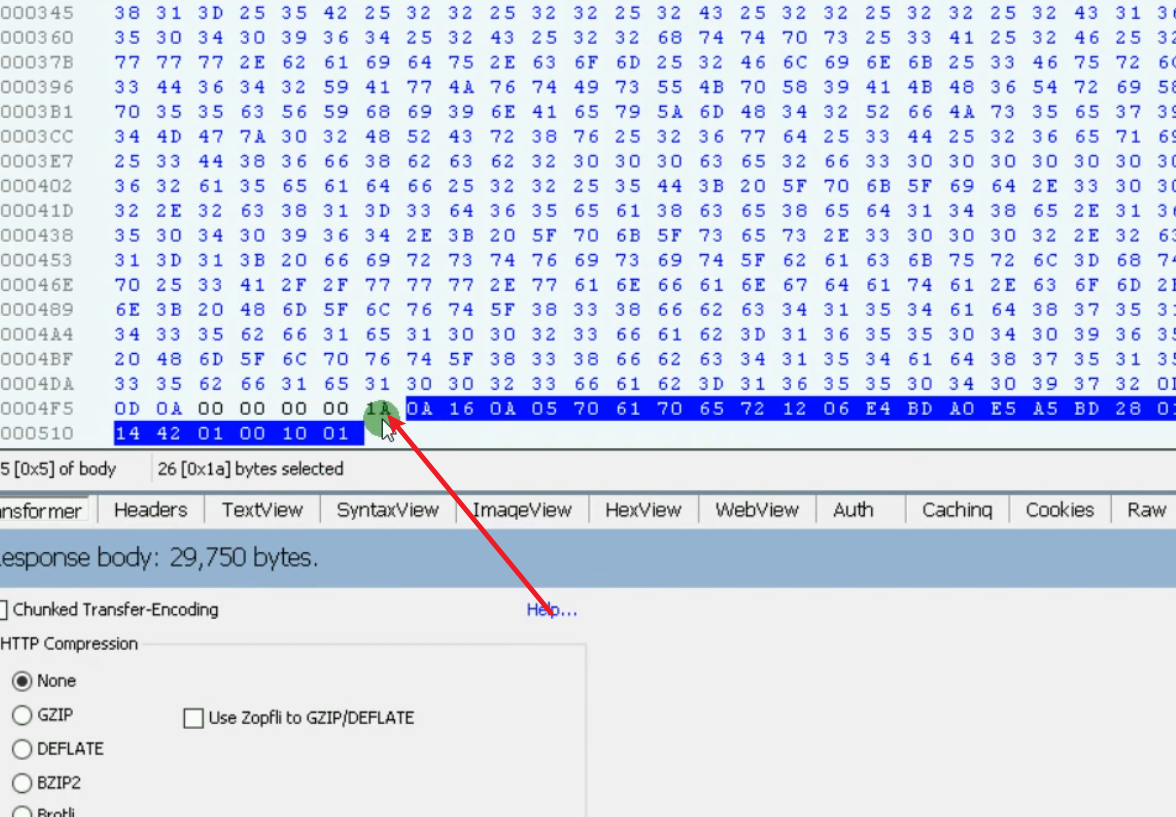
接下来这些都是固定写法,需要用到blackboxprotobuf进行序列化转换,值得注意的是 bytes_head 是请求长度,发送数据的时候需要携带,类似于填充长度一样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| import params_pb2 as pb
searchRequest = pb.SearchService.SearchRequest()
searchRequest.commonRequest.searchType = "paper"
searchRequest.commonRequest.searchWord = "python"
searchRequest.commonRequest.currentPage = 1
searchRequest.commonRequest.pageSize = 20
searchRequest.commonRequest.searchFilter.append(0)
searchSort = searchRequest.commonRequest.searchSort.add()
searchSort.B = " "
searchSort.C = 1
searchRequest.commonRequest.searchScope = 0
import struct
import requests
import blackboxprotobuf
url = 'https://s.wanfangdata.com.cn/SearchService.SearchService/search?'
headers = {
'origin': 'https://s.wanfangdata.com.cn',
'Content-Type': 'application/grpc-web+proto',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36',
'x-grpc-web': '1',
'x-user-agent': 'grpc-web-javascript/0.1'
}
bytes_body = searchRequest.SerializeToString()
bytes_head = bytes([0, 0, 0, 0, len(bytes_body)])
resp = requests.post(url=url, data=bytes_head + bytes_body, headers=headers)
data_len = struct.unpack(">i", resp.content[1:5])[0]
message, typedef = blackboxprotobuf.protobuf_to_json(resp.content[5:5 + data_len])
print(message)
|